


某国家级征信中心
目前,征信中心出具的信用报告已经成为国内企业和个人的“经济身份证”。截至2015年4月底,征信系统收录自然
人8.6亿多,收录企业及其他组织近2068万户。其中,信用评分是个人征信活动中最核心的数据分析手段。面对传统
信用评分方法陈旧、国外信用评分系统适用性差等问题,如何将大数据新算法应用于个人信用分数构建,以提升其准
确性、稳定性和可解释性?
人8.6亿多,收录企业及其他组织近2068万户。其中,信用评分是个人征信活动中最核心的数据分析手段。面对传统
信用评分方法陈旧、国外信用评分系统适用性差等问题,如何将大数据新算法应用于个人信用分数构建,以提升其准
确性、稳定性和可解释性?

客户简介
该国家级征信中心专门负责征信系统的建设、运行和维护的事业单位。
截至2015年4月底,其征信系统收录自然人8.6亿多,收录企业及其他组织近2068万户。
征信系统全面收集企业和个人的信息,形成了以企业和个人信用报告为核心的征信产品体系,征信中心出具的信用
报告已经成为国内企业和个人的“经济身份证”。
其中,信用报告数字解读作为征信报告的补充,运用统计分析方法,通过对个人的基本概况、信用历史记录、行为
记录、交易记录等大量数据进行分析,挖掘数据中蕴含的行为模式和信用特征,捕捉历史信息和未来信息表现之间
的关系,,以数字解读的形式对个人未来的某种信用表现做出综合评估。
截至2015年4月底,其征信系统收录自然人8.6亿多,收录企业及其他组织近2068万户。
征信系统全面收集企业和个人的信息,形成了以企业和个人信用报告为核心的征信产品体系,征信中心出具的信用
报告已经成为国内企业和个人的“经济身份证”。
其中,信用报告数字解读作为征信报告的补充,运用统计分析方法,通过对个人的基本概况、信用历史记录、行为
记录、交易记录等大量数据进行分析,挖掘数据中蕴含的行为模式和信用特征,捕捉历史信息和未来信息表现之间
的关系,,以数字解读的形式对个人未来的某种信用表现做出综合评估。
面临问题
该征信中心的信用报告数字解读体系参考了美国个人消费信用评估公司费埃哲研发 FICO 信用评分体系。
FICO信用评分体系构建于上世纪80年代,算法核心是逻辑回归,随着大数据建模技术和时代的发展,作用逐渐下降,
出现了模型老旧、信用分数区分度下降、存在刷分漏洞三方面的问题亟待解决。包括:
稳定性系数:在受政策影响较大的业务类型上,当前评分模型稳定性系数PSI较高。
预测性能:由于当前评分模型主要基于信贷行为开发,对于个人经营性贷款等业务的风险预测力稍差,对于满足可评分条件但信贷历史非常短的人群,可参考的信贷行为信息不足。
分数集中:对于只有一个信贷账户的人群,由于信贷行为同质化情况较多,导致部分分数段存在人群集中现象。
变量设计:当前进入模型的变量大多为减分变量,加分变量较少,从而导致信贷不活跃人群的评分偏高。
经济周期:模型较少考虑宏观经济周期的影响。
模型分组:如何保证人群在不同分组之间跳跃时分数波动较小。
FICO信用评分体系构建于上世纪80年代,算法核心是逻辑回归,随着大数据建模技术和时代的发展,作用逐渐下降,
出现了模型老旧、信用分数区分度下降、存在刷分漏洞三方面的问题亟待解决。包括:
稳定性系数:在受政策影响较大的业务类型上,当前评分模型稳定性系数PSI较高。
预测性能:由于当前评分模型主要基于信贷行为开发,对于个人经营性贷款等业务的风险预测力稍差,对于满足可评分条件但信贷历史非常短的人群,可参考的信贷行为信息不足。
分数集中:对于只有一个信贷账户的人群,由于信贷行为同质化情况较多,导致部分分数段存在人群集中现象。
变量设计:当前进入模型的变量大多为减分变量,加分变量较少,从而导致信贷不活跃人群的评分偏高。
经济周期:模型较少考虑宏观经济周期的影响。
模型分组:如何保证人群在不同分组之间跳跃时分数波动较小。
如何解决
基于3.7亿全量信用报告数据,通过大数据新算法从信用报告中提取上千个维度的信息,针对解决之前体系的各种问
题,对征信中心进行信用评分体系优化。
同时探索多种机器学习算法,实现系统稳定性、准确性、业务指示性实现全面提升。
该项目的建模数据包括2010年7月31日前的贷款记录、贷记卡、准贷记卡记录、特殊交易记录、与查询记录,表现
变量来自2010年7月31日至2012年7月31日之间的逾期记录。样本人群共1千2百万,由征信中心进行抽样选取。 信
用评分建模分析共分为以下几个步骤:
数据预处理与质量评估:各个变量的异常值与离群值的识别和分析、字段逻辑一致性的检验等;
统计变量计算:评分模型中包括了1133个风险变量,分为7大类指标;
构建预测模型:模型表现变量选取未逾期样本为0,逾期90天以上样本为1,以700万样本为训练集,300万样本为测
试集,分别使用逻辑回归、决策树、随机森林、Adaboost、GBDT、SVM构建分类模型;
分数转化:将分类模型生成的预测违约率转化为0到100的分数,分数满足正态分布。
题,对征信中心进行信用评分体系优化。
同时探索多种机器学习算法,实现系统稳定性、准确性、业务指示性实现全面提升。
该项目的建模数据包括2010年7月31日前的贷款记录、贷记卡、准贷记卡记录、特殊交易记录、与查询记录,表现
变量来自2010年7月31日至2012年7月31日之间的逾期记录。样本人群共1千2百万,由征信中心进行抽样选取。 信
用评分建模分析共分为以下几个步骤:
数据预处理与质量评估:各个变量的异常值与离群值的识别和分析、字段逻辑一致性的检验等;
统计变量计算:评分模型中包括了1133个风险变量,分为7大类指标;
构建预测模型:模型表现变量选取未逾期样本为0,逾期90天以上样本为1,以700万样本为训练集,300万样本为测
试集,分别使用逻辑回归、决策树、随机森林、Adaboost、GBDT、SVM构建分类模型;
分数转化:将分类模型生成的预测违约率转化为0到100的分数,分数满足正态分布。
实施效果
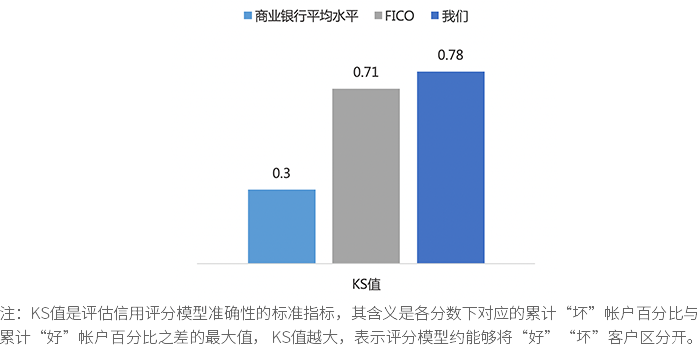
新一代模型对好坏账户的区分度远高于行业平均水平。
对未来24月违约的预测准确率达到95%,对好坏人群区分度的KS指标达到78%。
对未来24月违约的预测准确率达到95%,对好坏人群区分度的KS指标达到78%。
准备好开始大数据升级了吗?
联系我们


